前言
布隆过滤器(Bloom Filter)是1970年由布隆提出的一种数据结构,它本质上是一个很长的二进制位数组和一系列随机映射函数。这种数据结构主要用于检索一个元素是否在一个集合中,其优点在于空间效率和查询时间都比一般的算法要好得多,同时散列函数相互之间没有关系,方便由硬件并行实现。然而,布隆过滤器也存在一些缺点,比如有一定的误识别率,并且删除元素比较困难。
在具体实现上,布隆过滤器并不直接存储数据本身,而是通过多个哈希函数对要存储的数据进行哈希运算,并将哈希运算的结果作为位数组的下标,将对应的数组元素修改为1。因此,布隆过滤器不需要存储元素本身,这在某些对保密要求非常严格的场合具有优势。
布隆过滤器的应用场景非常广泛。例如,在避免缓存穿透的场景中,当使用Redis等缓存系统时,如果缓存中没有命中,通常需要查询数据库。如果查询量非常大,会对数据库造成压力。此时,可以使用布隆过滤器来减少不必要的数据库查询,从而减轻数据库的压力。另外,布隆过滤器还可以用于判断用户是否是刷单用户,是否在黑名单池内等场景。
介绍
快速启动
布隆过滤器常用于解决缓存穿透问题,平常我们可以使用Google Guava库中的BloomFilter类、Apache Commons库中的BloomFilter类等来创建布隆过滤器,示例代码如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| public class BloomFilterExample {
public static void main(String[] args) {
BloomFilter<Integer> bloomFilter = BloomFilter.create(Funnels.integerFunnel(), 1000, 0.01);
bloomFilter.put(123);
bloomFilter.put(456);
bloomFilter.put(789);
System.out.println(bloomFilter.mightContain(123));
System.out.println(bloomFilter.mightContain(999));
}
}
|
原理
布隆过滤器可以看作是一个bits为n的bitmap,同时有k个哈希函数。 当一个元素加入位图时,通过k个hash函数将元素映射到位图的k个点,并把它们置1;当检索时,再通过k个hash函数运算检查位图的k个点是否都为1;如果有不为1的点,那么认为该key不存在;如果全部为1,则可能存在。 同时可能存在误判的情况,即k个点均为1,而实际上该key并不存在布隆过滤器中。
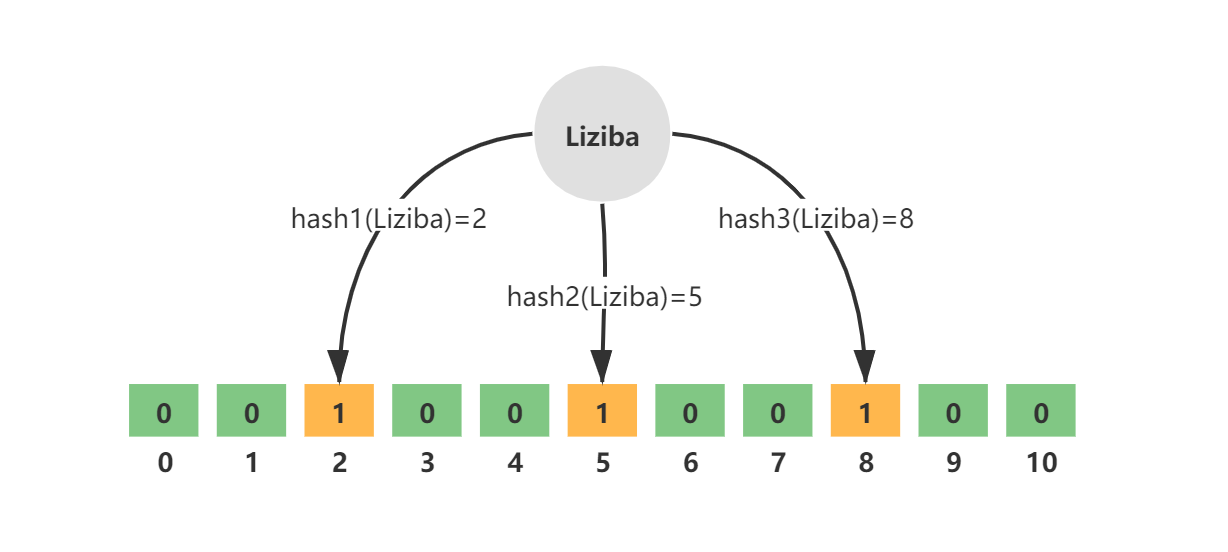
布隆过滤器的误判率,主要取决于bitmap的大小和hash函数的个数以及设计。 正常我们在使用布隆过滤器的时候,是给定预期数据量n和误判率p,然后动态生成我们所需要的布隆过滤器。 计算公式如下: 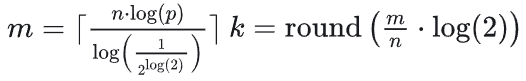 得到bitmap的大小m和所需哈希函数个数k之后,我们便可以开始构造属于我们的布隆过滤器了
得到bitmap的大小m和所需哈希函数个数k之后,我们便可以开始构造属于我们的布隆过滤器了
代码实现
定义布隆过滤器接口
定义布隆过滤器的接口类,方便程序的扩展和后续的使用
1
2
3
4
5
6
7
8
9
10
|
public interface BloomFilter {
public void add(Object value);
public boolean contains(Object value);
}
|
实现简单布隆过滤器
属性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
private int size;
private int k;
private List<Integer> SEEDS ;
private BitSet bits ;
private ArrayList<SimpleHash> func = new ArrayList<>();
|
简单布隆过滤器 接收位数组大小和哈希函数个数
1
2
3
4
5
6
7
8
9
10
11
| public SimpleBloomFilter(int size,int k){
this.size = size;
this.k = k;
this.bits = new BitSet(size);
SEEDS = PrimeNumbers.getKDistinctPrimes(k);
for(int seed :SEEDS){
func.add(new SimpleHash(size,seed));
}
}
|
定义哈希类
根据上文所述,我们需要k个哈希函数,在此我们定义一个SimpleHash类,给定bitmap容量和随机数种子之后可以动态的生成一个hash函数
注意:
需要给定bitmap的容量是因为我们的hash函数生成的hashcode的范围应该在(0,m-1)
种子最好为质数
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
public static class SimpleHash{
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
public int hash(Object value){
int h;
return(value == null)?0:Math.abs(seed*(cap-1)&((h = value.hashCode())^(h>>>16)));
}
}
|
质数生成器
我们需要一个相对均匀的质数数组,所以我们实现一个简单的质数生成器,每个质数之间的间隔大于20,以确保它相对来说均匀
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
| public class PrimeNumbers {
public static List<Integer> getKDistinctPrimes(int k){
List<Integer> primes = new ArrayList<>();
int num = 2;
while(primes.size() < k){
if(isPrime(num)&&isWellDistributed(num,primes)){
primes.add(num);
}
num++;
}
return primes;
}
private static boolean isPrime(int num) {
if (num <= 1) {
return false;
}
if (num <= 3) {
return true;
}
if (num % 2 == 0 || num % 3 == 0) {
return false;
}
int sqrtNum = (int) Math.sqrt(num);
for (int i = 5; i <= sqrtNum; i += 6) {
if (num % i == 0 || num % (i + 2) == 0) {
return false;
}
}
return true;
}
private static boolean isWellDistributed(int num, List<Integer> primes) {
for (int prime : primes) {
if (Math.abs(prime - num) < 20) {
return false;
}
}
return true;
}
}
|
实现接口方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
@Override
public void add(Object value) {
for(SimpleHash f:func){
bits.set(f.hash(value));
}
}
@Override
public boolean contains(Object value) {
boolean ret = true;
for(SimpleHash f:func){
ret = ret && bits.get(f.hash(value));
}
return ret;
}
|
实现布隆过滤器工厂
布隆过滤器工厂接收预期数据量n和误差率p,根据上面两个数据计算出布隆过滤器的大小m(size)和哈希函数个数k。通过布隆过滤器工厂创建布隆过滤器可以简化布隆过滤器的使用
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| public class BloomFilterFactory {
public static BloomFilter createBloomFilter(int n,double p){
int size = getSizeOfBloomFilter(n,p);
int k = getNumberOfHashFuc(size,n);
return new SimpleBloomFilter(size,k);
}
private static int getSizeOfBloomFilter(int n, double p) {
int size = (int) Math.ceil(-(n * Math.log(p)) / Math.pow(Math.log(2), 2));
return size;
}
private static int getNumberOfHashFuc(int size, int n) {
int k = (int) Math.ceil((size / (double) n) * Math.log(2));
return k;
}
}
|
程序中实际应用布隆过滤器
程序执行逻辑梳理: 请求到来之后在Server到Redis之间插入布隆过滤器,先判断数据是否存在,存在再执行接下来的步骤,不存在则直接返回。同时在每次查询到数据结果之后,布隆过滤器添加该key。
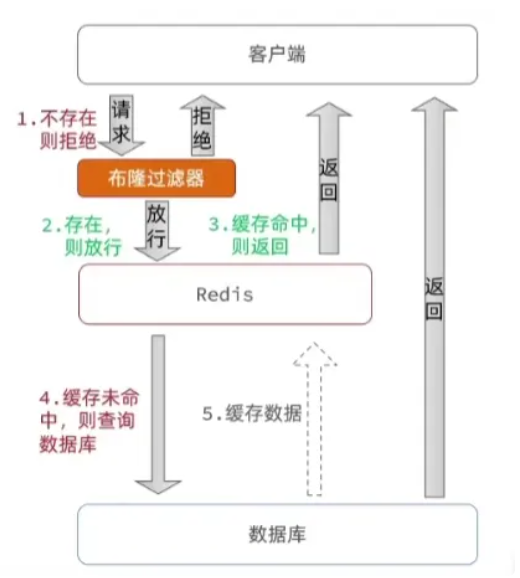
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| loomFilter myBloomFilter = BloomFilterFactory.createBloomFilter(1000,0.001);
@PostConstruct
public void init(){
List<Shop> shops = shopMapper.selectList(null);
for (Shop shop : shops){
myBloomFilter.add(shop.getId());
}
}
@Override
public Result queryById(Long id) {
if(!myBloomFilter.contains(id)){
return Result.fail("不包含这个id");
}
String key = "cache:shop:" + id;
String shopJson = stringRedisTemplate.opsForValue().get(key);
if (StrUtil.isNotBlank(shopJson)){
Shop shop = JSONUtil.toBean(shopJson,Shop.class);
return Result.ok(shop);
}
Shop shop = getById(id);
if (shop == null){
return Result.fail("商铺不存在!");
}
stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop));
stringRedisTemplate.expire(key,30+RANDOM_EXPIRE_TIME, TimeUnit.MINUTES);
return Result.ok(shop);
}
|
自扩容布隆过滤器
当布隆过滤器实际的数据存储量超过预期数据量之后,误判率也会随之上涨。 但是布隆过滤器是不能删除已有元素的,在这里我们采取的方案是再创建一个布隆过滤器 添加操作在最新的布隆过滤器中执行,contain操作在所有的布隆过滤器中执行 代码实现如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| **
* 自适应布隆过滤器,当满了的时候实现自动扩容
*/
public class AdaptBloomFilter implements BloomFilter{
private int n;
private double p;
public AdaptBloomFilter(int n, double p){
this.n=n;
this.p=p;
this.bloomList.add(BloomFilterFactory.createBloomFilter(n,p));
}
private ArrayList<BloomFilter> bloomList = new ArrayList<>();;
private int count=0;
@Override
public void add(Object value) {
bloomList.get(bloomList.size()-1).add(value);
if (count++>n){
expand();
}
}
@Override
public boolean contains(Object value) {
for (BloomFilter i : bloomList){
if (bloomList.contains(value)){
return true;
}
}
return false;
}
private void expand(){
this.bloomList.add(BloomFilterFactory.createBloomFilter((int) (n),p));
n= (n*2);
}
|